Basically, his theory is that by spoofing the IP address of a victim, and sending an HTTP GET request to a webserver for a file larger than the request he is achieving amplifacation. This is illustrated in the following diagram, A(C) represents the attacker (host A), spoofing the victims ip (host C) and requesting an image from the webserver (host B).
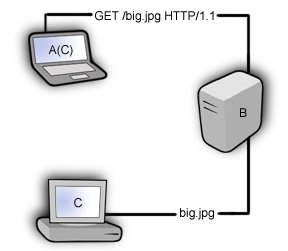
Assuming the file big.jpg is bigger than the HTTP request packet, his transmission has been amplified, and since his IP has been spoofed big.jpg will be sent to the victim. A standard http get request from a browser can be anywhere from 100-500 bytes, but a lot of this information, the useragent, referrer, etc, is unnecessary. All we really need to send in this case is the request method, URI and HTTP version.
GET /big.jpg HTTP/1.1
This will end up being around 50 bytes. If the image we're requesting is 5k we've amplified our attack by 100x. Having a look at google's image search gives indication that images over 500k are not uncommon. Looks pretty dangerous, right? An attacker can send out 50 bytes of data and have a victim recieve 500000 bytes. Or can they?
The problem is that the designer of this DoS doesn't understand the technology he's attempting to exploit.
Problem 1: Fragmentation.
Even if he could get this exploit to work (he can't, but I'll get to that) his metrics are off. Webservers don't just send out 500000 byte packets. These will be fragmented into more manageable pieces. The standard maximum size for a packet is 1500 bytes. Each 1500 byte fragment has to be acknowledged by the recipient but since this fragment isn't expected by the victim host it is discarded and an RST packet is sent back to the webserver, reseting the connection. That chokes our amplification to a maximum of 1500 bytes for each request (1500 is the STANDARD mtu, but in certain circumstances can be modified). This minimizes the risk significantly.
Problem 2: TCP isn't stupid.
This attack tries to take advantage of the fact that an HTTP GET request is relatively small, but has the potential to force large responses from a server. He's got the right idea, but he's looking at the wrong transmission protocol. TCP is connection based, and as such any TCP service requires a full two-way connection. Spoofing packets is easy, but spoofing a full connection is not. In order to have the webserver accept and respond to the GET request for this image, the attacker has to first complete the tcp initiation process (or threeway handshake) posing as the victim like this:
A(C) >-------SYN-------> B
B >-----SYN/ACK-----> C
A(C) >-------ACK-------> A
Those who know TCP will know that this is not an easy thing to do. The attacker is faced with a number of problems, but first and foremost is sequence numbers. I'll illustrate:
A(C) >-------SYN------[S:1111111111 / A:0000000000]------> B
B >-----SYN/ACK----[S:2222222222 / A:1111111112]------> C
A(C) >-------ACK------[S:1111111112 / A:2222222223]------> A
This is what needs to happen, not what will happen. Here's what will happen.
A(C) >-------SYN------[S:1111111111 / A:0000000000]------> B
B >-----SYN/ACK----[S:2222222222 / A:1111111112]------> C
A(C) >-------ACK------[S:1111111112 / A:uhmmmmmmmm]------> A
Our attacker will have no way of knowing the sequence number generated by the webserver as it was sent to the victim, not him. This, of course, is debatable. Okay, so lets debate it.
Michael Zalewski did some excellent research on ISN (Initial Sequence Number) randomness in various operating systems. His research shows that there are a number of TCP implementations using weak, predictable ISNs. If the ISN can be predicted, than the TCP connection can be spoofed! But what does this mean for the DoS? Nothing. Weak ISN's can be predicted but very rarely to absolute precision. This means that multiple guesses have to be made.
A(C) >-------SYN------[S:1111111111 / A:0000000000]------> B
B >-----SYN/ACK----[S:2222222222 / A:1111111112]------> C
A(C) >-------ACK------[S:1111111112 / A:1111111110]------> A
A(C) >-------ACK------[S:1111111112 / A:1111111111]------> A
A(C) >-------ACK------[S:1111111112 / A:1111111112]------> A
A(C) >-------ACK------[S:1111111112 / A:1111111113]------> A
...
Some of the weakest ISN's still require around 5000 guesses, meaning 5000 packets. ACK packets are usually about 50 bytes. Thats 250000 bytes of data being sent for every 1500 bytes reflected.
Now, not to add insult to injury, but lets say our attacker CAN guess the sequence number without having to send more than 1500 bytes. I mean, I suppose its feasable that he finds a webserver on a network generating absolutely predictable ISNs. (barely, but we're scientists.) there's something ELSE he's missing. When the webserver (host B) sends the SYN/ACK to the victim (host C), the victim's machine knows it didn't request a connection, assumes the webserver has malfunctioned and sends an RST back. This tips off the webserver, causing it to not send the 1500 byte fragment of our image.
A(C) >-------SYN-------> B
B >-----SYN/ACK-----> C
C >-------RST-------> B
The only way to effectively spoof a full connection, is if you can "gag" the host who's address you're spoofing, so that it can't reply. So, really... you have to DoS the victim in order to use this DoS against them! The attack is entirely superfluous.
Now, if you're looking for this kind of reflective amplification DoS, try looking at UDP services with the same small request/large reply type features.
;)


No comments:
Post a Comment