You've all seen Johnny Long's google hacking database
Its an excellent example of a full disclosure platform that helps raise awareness about vulnerabilities in the wild. I just launched the first version of the csrf hacking database here:
http://csrf.0x000000.com/csrfdb.php
I designed, developed and am maintaining it on my own right now so go easy on me ;)
thanks to Ronald van den Heetkamp for the hosting.
EDIT:
http://h4k.in/csrf now forwards to the csrf database as well
Thanks to Mario Heiderich for the redirect as well as for his suggestions and help.
Sunday, May 20, 2007
Wednesday, April 25, 2007
l33t haxxors
I dont usually post on nontechnical subjects, but I'm making an exception:
l33t haxxors - Episode 1
l33t haxxors - Episode 2
l33t haxxors - Episode 3
Excellent comic relief for a tough day. Enjoy :)
l33t haxxors - Episode 1
l33t haxxors - Episode 2
l33t haxxors - Episode 3
Excellent comic relief for a tough day. Enjoy :)
Tuesday, April 24, 2007
The Ellusive Negative Quantity Vulnerability
I guess I'm just going to pick up where I left off a few months back. Rather than backtracking over all the stuff thats happened between then and now, I'll just keep on posting as things come up.
So here's one that just sorta came to me as I was pen-testing a browser based php mmorpg with a friend. I expect this type of vulnerability exists in more problematic places: Banking systems, shopping cart systems, etc.
The vulnerability is a sort of logic error. Lets have a look at some psuedo code designed to allow customers to make purchases.
We give the customers $100 to start and we create an object worth 10$.
We ask the customer how many of the object they want to buy.
We calculate the total price for all the objects, and check whether or not the customer can afford it.
If they can we take the total price and subtract it from the customers money.
The subtraction operation is where the problem exists. What happens when we supply a negative quantity? Well lets run through it:
With a quantity of -10, the total price becomes -10 * 10 = -100
We check if the total price is more than I have in my wallet, ...its not, its less.
So we take that total price, and subtract it from the customers money: 1000 - -100 = 1100
WAIT, see that? using a negative quantity, we have actually GAINED money.
There's a simple solve. And its a solution thats repeated over and over again in web/all security. WHITELISTING. Only allow good input. Theres no need for a negative quantity, so don't allow them. I'm surprised I havn't seen more of this poor logic type vulnerability. Anyone else have similar stories?
<3
So here's one that just sorta came to me as I was pen-testing a browser based php mmorpg with a friend. I expect this type of vulnerability exists in more problematic places: Banking systems, shopping cart systems, etc.
The vulnerability is a sort of logic error. Lets have a look at some psuedo code designed to allow customers to make purchases.
let $Customers_Money = 100
let $Object_Price = 10
let customer input value for $Quantity
let $Total_Price = $Object_Price * Quantity
if $Total_Price > $Customers_Money then tell customer its too much, and exit
else let $Customers_Money = $Customers_Money - $Total_Price
We give the customers $100 to start and we create an object worth 10$.
We ask the customer how many of the object they want to buy.
We calculate the total price for all the objects, and check whether or not the customer can afford it.
If they can we take the total price and subtract it from the customers money.
The subtraction operation is where the problem exists. What happens when we supply a negative quantity? Well lets run through it:
With a quantity of -10, the total price becomes -10 * 10 = -100
We check if the total price is more than I have in my wallet, ...its not, its less.
So we take that total price, and subtract it from the customers money: 1000 - -100 = 1100
WAIT, see that? using a negative quantity, we have actually GAINED money.
There's a simple solve. And its a solution thats repeated over and over again in web/all security. WHITELISTING. Only allow good input. Theres no need for a negative quantity, so don't allow them. I'm surprised I havn't seen more of this poor logic type vulnerability. Anyone else have similar stories?
<3
Tuesday, October 24, 2006
Defeating Dean Edwards' Javascript Packer
Today a friend passed me some obfuscated javascript and asked if I would help him decode it. I had a quick look at it and saw the following code fragment:
eval(function(p,a,c,k,e,d){ ...
This made me smile. p,a,c,k,e,d... Cute. After a little research, I found this to be a signature function of Dean Edwards javascript packer. I found 2 very quick ways to deobfuscate code packed with this packer, and I have decided to share them with you. By presenting this my intention is NOT to insult Dean's work in any way, when it comes to javascript, and a few other topics, Dean is lightyears ahead of me. I present this to provide the community with a few methodologies they might use to approach these scenarios in the future, should it be necessary.
Here's a link to the packer:
http://dean.edwards.name/packer/
The first method does not attack the obfuscation technique, but a feature of the packer interface. Built RIGHT IN to the interface is a decode button. This has been designed to only allow decoding of your own code. If you look at the interface, you can't paste into the top textarea (because of the readonly attribute) and the decode button is disabled until you've actually packed something. This design is inherently flawed as it depends on the browser.
I wrote a bookmarklet called reEnable that will remove the readonly attribute from textfields and the disabled attribute from other html elements.
reEnable: Bookmark this :)
Using reEnable you can paste obfuscated code into the interface and decode it with a click.
The second method attacks a weakness in the obfuscation technique itself. Here is some code
unpacked:
and packed:
(I had to force multiple lines to avoid it breaking my layout lol)
it looks like a lot of randomness, but the weakness is pretty easy to spot if you know what you're looking for.
Notice near the bottom all the code is there, just rearanged with the syntax punctuation removed? if you look even closer the syntax punctuation is there as well, only seperate from the strings. If we looked at this long enough, we might be able to write a utility to unpack it... but there's an even easier way. Notice how everything is wrapped in an eval()? well, we don't want the code to be evaluated, we want to SEE it... If you replace the opening eval( with document.write( ... all the code is dumped to the screen. If some of it is being interpereted as html rather than being displayed consider forcing your document.write to write between <textarea></textarea> tags.
<3
eval(function(p,a,c,k,e,d){ ...
This made me smile. p,a,c,k,e,d... Cute. After a little research, I found this to be a signature function of Dean Edwards javascript packer. I found 2 very quick ways to deobfuscate code packed with this packer, and I have decided to share them with you. By presenting this my intention is NOT to insult Dean's work in any way, when it comes to javascript, and a few other topics, Dean is lightyears ahead of me. I present this to provide the community with a few methodologies they might use to approach these scenarios in the future, should it be necessary.
Here's a link to the packer:
http://dean.edwards.name/packer/
The first method does not attack the obfuscation technique, but a feature of the packer interface. Built RIGHT IN to the interface is a decode button. This has been designed to only allow decoding of your own code. If you look at the interface, you can't paste into the top textarea (because of the readonly attribute) and the decode button is disabled until you've actually packed something. This design is inherently flawed as it depends on the browser.
I wrote a bookmarklet called reEnable that will remove the readonly attribute from textfields and the disabled attribute from other html elements.
reEnable: Bookmark this :)
Using reEnable you can paste obfuscated code into the interface and decode it with a click.
The second method attacks a weakness in the obfuscation technique itself. Here is some code
unpacked:
document.write('Hello World!');
and packed:
eval(function(p,a,c,k,e,d){e=function(c){
return c};if(!''.replace(/^/,String)){while
(c--){d[c]=k[c]||c}k=[(function(e){return
d[e]})];e=(function(){return'\\w+'});c=1}
;while(c--){if(k[c]){p=p.replace(new
RegExp('\\b'+e(c)+'\\b','g'),k[c])}}return
p}('3.0(\'1 2!\');',4,4,'write|Hello|World
|document'.split('|'),0,{}))
(I had to force multiple lines to avoid it breaking my layout lol)
it looks like a lot of randomness, but the weakness is pretty easy to spot if you know what you're looking for.
Notice near the bottom all the code is there, just rearanged with the syntax punctuation removed? if you look even closer the syntax punctuation is there as well, only seperate from the strings. If we looked at this long enough, we might be able to write a utility to unpack it... but there's an even easier way. Notice how everything is wrapped in an eval()? well, we don't want the code to be evaluated, we want to SEE it... If you replace the opening eval( with document.write( ... all the code is dumped to the screen. If some of it is being interpereted as html rather than being displayed consider forcing your document.write to write between <textarea></textarea> tags.
<3
Friday, September 15, 2006
Chasing Wild Geese? ...Keep Chasing.
I'm BACK! Sorry for the hiatus, I was preparing for and starting school. Now that things have gotten into a bit of a groove, I can get back on the HACK. The title for todays post is sort of tongue-in-cheek. I spent a lot of time chasing my tail on this particular project, and what fun would I be if I couldn't have a laugh at my own expense? The main point is that, even though I got stopped up a few times... I didn't give up, and in the end I got positive results.
My friend Dustin passed me the source for a c program he developed. Its purpose is to encrypt files. After looking it over, I told him I could defeat his encryption and he told me to give it a try, here's how the project played out. (keep in mind, I'm not a cryptanalyst... and I might very well be missing something or even dead wrong, therefore I'd LOVE to hear from anyone with advice or constructive criticism.)
The program is shush.c, and this is how it works. You provide the program with two pieces of information, the name of the file to encrypt and an integer in the set 0 - 3435973836. This integer becomes your KEY. Shush then encrypts the file using an XOR encryption scheme. If you don't know what XOR is, or you don't have a very good grasp of XOR read wikipedias entry for truth tables. Right away, you're probably seeing the #1 problem with this encryption scheme. Too small a keyspace, or in other words, there are so few possible keys that this can be easily brute forced.
Lets examine: there are approximately 3.4 billion possible keys (0-3435973836). Compare this to a simple 8 character password using only characters from the set [a-z]. The keyspace here is 26^8 or 208827064576 which is over 208 billion possible keys. How long would it take your password cracker to incrementally crack a password that was known to be 8 characters in the set [a-z]? Not very long, and that password is over 65 times stronger than any key for this program.
Now here's the difference between hacking and ...cracking or whatever other awkward label you use. I could stop here, write a little program to implement the brute forcing and be done with it, or I could keep hacking at it to see if there's an even more efficient way. You know me, of course I'll keep going... And heres where all the trouble started ;)
Lets take a look at how shush uses the key to encrypt the file (the shush.c source is available below this description, use it as a reference). When you give shush your integer, shush passes it to a function called srand(). This function uses the integer as an initial value for generating "random" numbers with the rand() function. This concept is called seeding. To be as basic as I possibly can... The SEED is a number that the random number generator does weird math stuff with. Once its done its weird math stuff, the result is the random number thats been generated, that result ALSO becomes the new seed. Here's some psuedo code to represent this:
seed = 31337
Generate random number:
random_number = seed + 1234 * 4321 / 7
seed = random_number
Now this is VERY arbitrary. The "weird math stuff" is actually quite technical, but far from within the scope of this post. For more information on this stuff research Linear congruential generators.
The point to note here is that this "weird math stuff" is an algorithm, and if you think about it... there is nothing truly "random" about mathematical algorithms. Thats why we call this algorithmic randomness "psuedorandom". And we call this generator a "psuedorandom number generator" (hereafter PRNG).
It might seem like i'm on a tangent, but trust me its relevant.
So, basically You give shush an integer, this integer becomes a SEED. Shush then gets into a loop. This loop reads in one byte, and performs an XOR operation on that byte against the result of a call to the PRNG. This PRNG is actually the function rand(). Keep that psuedo code in mind, everytime rand() is called, the seed changes, and so, the next time its called the result is different. The result of this XOR operation becomes the value for the encrypted byte, and so is written out to the encrypted file.
Here is shush.c
If you're following me, this will make sense. Based on the fact that rand() uses a static algorithm, the sequence of numbers it returns will always be the same sequence for a particular seed. With a symmetrical stream cipher like this XOR scheme, this is useful. I'll demonstrate.
Lets look at this sequence of numbers: 1, 2, 3, 4. We'll use them to "XOR encrypt" these 4 values: 5, 5, 5, 5. In a realworld example, these numbers would be numerical representations of the byte's from the file.
as XOR is a bitwise operator, Lets see these in binary form:
00000101 00000101 00000101 00000101 (5, 5, 5, 5: unencrypted)
00000001 00000010 00000011 00000100 (1, 2, 3, 4: KEY)
-------------------------------------------------------------
00000100 00000111 00000110 00000001 (4, 7, 6, 1: encrypted)
This is what happens when you run shush on a file... Now, you send that file to someone and they run shush with the same key, and this happens:
00000100 00000111 00000110 00000001 (4, 7, 6, 1: encrypted)
00000001 00000010 00000011 00000100 (1, 2, 3, 4: KEY)
-----------------------------------------------------------
00000101 00000101 00000101 00000101 (5, 5, 5, 5: decrypted!)
This is the concept of a symetrical encryption scheme. Now lets review what we know. The user supplies an integer. This integer seeds rand(). Rand generates a sequence of numbers against which each byte in the file is XOR'd, the results make up the encrypted file.
Now that we understand shush more thoroughly, we can design an attack. My theory was this:
The user supplies a key that seeds rand(), rand() then returns a predefined algorithmic series of numbers. Since this is algorithmic, given any number in the series, I will be able to predict the next number, or even the previous number in the series. Therefore if ANY of those numbers are known to me, I can reverse the algorithm to get the key. With that key, I can decrypt the file. This is pretty standard, the question is how can I find any of these numbers? Well, really I shouldn't be able to... but a weakness in the implementation gives me a leg up. When a file is encrypted with shush, it keeps its filename. This means that, for a lot of file formats, SOME of the plaintext characters will be known. For instance, every valid JPG will have the same first 4 bytes (have a look if you want to verify). These are file headers. The nature of XOR allows us to use these known values to extract part of the key!
(OKAY WAIT. Here is where we're going to get mixed up with our terminology... when I say "key" I'm talking about the integer the user gave to shush. When I say "part of the key" i'm not talking about part of that number, I'm talking about one value returned by rand()... This might be confusing, but assume the integer supplied by the user to be 'the same thing' as the series of numbers returned by rand(). )
Lets look at how this works. Lets say we're looking at the first four bytes of the encrypted file (same values as the last examples) and in this case we KNOW (based on file format specifications) that these bytes were originally 5, 5, 5, 5 before being encrypted.
00000100 00000111 00000110 00000001 (4, 7, 6, 1: encrypted)
00000101 00000101 00000101 00000101 (5, 5, 5, 5: unencrypted)
-------------------------------------------------------------
00000001 00000010 00000011 00000100 (1, 2, 3, 4: KEY!)
Now that we've extracted some of the numbers returned by rand(), all we need to do is reverse the algorithm in rand() to determine what key was given to srand(), and the encryption is defeated. This is A LOT faster than brute forcing... Everything looks good Right? hmm....
If anyone see's a problem here you get props. I didn't see a problem until I started experimenting. My theory seems pretty solid, but (my c++ prof loves to call me on this) I'm making an assumption. XOR is bitwise. Shush takes 1 byte from the file, and XOR's it against 1 integer returned by rand(). Until now, we've been assuming that both of these peices of data were of the same size. Thats assuming that rand() can only generate 8bit integers, making the maximum value 255 (unsigned). This isn't the case, after experimenting with rand() for a bit, its clear that rand() returns values outside that range. So lets see what happens when we XOR two values with different bit lengths, we'll use the same values as before, but we'll change one number from the key:
00000101 00000101 00000101 000000101 (5, 5, 5, 5 : unencrypted)
00000001 00000010 00000011 110010000 (1, 2, 3, 400: KEY)
-------------------------------------------------------------
00000100 00000111 00000110 110010101 (4, 7, 6, 405: encrypted)
Notice that the fourth value returned by rand() this time is to 400, this makes the bit length 9 instead of 8. Since the key changed in bit length, a 0 was padded to the beginning of the value it is being XOR'd against, and the encrypted value ends up being 9 bits as well. Since we're writing byte values out to a file, only 8 of those bits will actually be used, 1 will be discarded. Lost Forever. This complicates our methodology, watch (remember the encrypted value was 110010101, or 405, but when the most significant bit is discarded, it becomes 10010101, or 149):
10010101 (149: encrypted)
00000101 (5 : Known unencrypted value)
--------------------------------------
10010000 (144: key? ...)
Flawed logic gave us a false positive. the key is 400, not 144... So if rand() returns a value greater than 255, our attack fails. Right? well... To an extent. Think of it on a bit level... The value of the actual key, versus the value or the key we got are actually pretty close when we look at it this way:
110010000
10010000
Basically, we still know the last 8 bits of the key no matter what. So we could build a set of potentials based how many values rand() can return that end in our 8 bits. In order to do this we need to know the largest possible value rand() can give us. This value changes from compiler to compiler (remember this, I'll come back to it.) and its set in cstdlib/stdlib.h as RAND_MAX. In the compiler I use (mingw), it's set to 0x7fff, or 32767 which is 15 bits. So how many potential values exist when the last 8 bits are known? 2^7 == 128 possible values. Thats a pretty small keyspace, compared to the 3.4 billion we were dealing with before...
Incase anyones lost, quick review:
We xor a byte from the encrypted file against what we KNOW was the original byte before it was encrypted. The result becomes the final 8 bits of what that byte was originaly xor'd with by shush. This gives us a set of 128 potential values. Now we can reverse the algorithm in rand(), and determine 128 potential keys one of which was originally supplied to shush by the user.
If anyone see's a problem HERE, again... props. There's something I didn't take into account. We've been assuming that in rand() is a symmetrical algorithm that can be reversed. I think the reason I thought this was because in most descriptions of rand(), they talk about algorithmic randomness, and in pure mathematics algorithms are symmetrical but in programming, not necesarilly. Here is what rand() does (this is the implementation used by mingw, it also changes between compilers, I've also changed how it looks a bit for simplicity, it still functions the same.)
return((seed = seed * 214013L + 2531011L) >> 16);
As you can see, it takes the seed (your key) and multiplies it by 214013, the product of that is added to 2531011. If this was all, it could be trivially reversed. We'd take the result, subtract 2531011 and divide the difference by 214013. But there's more. >> 16 indicates that 16 bits are dropped off the end of the value... And again, lost forever. So this introduces a whole new set of potentials... How many? well... remember the maximum allowed seed (as indicated by shush) is: 3435973836, which is a 32bit value. 16 of those bits are discarded from the seed. This means that for every number from our list of 128 potentials there is 2^16 or 65536 additional potentials. This gives us 8388608 potentials in all. Still beats brute-forcing.
Their's a question to ask yourself at this point though. A modern computer can crunch 3.4 billion numbers in seconds. So does the difference in efficiency and execution time justify the complexity of the code required to accomplish it? Probably not to the average user. If this was a professional developer project, your boss would kick you in the ass for wasting so much time. But it was a lot of fun anyways.
One side note is that shush is depending on rand(). Through my research, I learned that rand() has no standard. Its implemented differently on many different platforms, and in different compilers, and even changes from version to version. This program would be mostly useless if it was released opensource, as if two users compiled it with different compilers, chances are it would fail.
Anyways, hope SOMEONE had fun reading this lol
My friend Dustin passed me the source for a c program he developed. Its purpose is to encrypt files. After looking it over, I told him I could defeat his encryption and he told me to give it a try, here's how the project played out. (keep in mind, I'm not a cryptanalyst... and I might very well be missing something or even dead wrong, therefore I'd LOVE to hear from anyone with advice or constructive criticism.)
The program is shush.c, and this is how it works. You provide the program with two pieces of information, the name of the file to encrypt and an integer in the set 0 - 3435973836. This integer becomes your KEY. Shush then encrypts the file using an XOR encryption scheme. If you don't know what XOR is, or you don't have a very good grasp of XOR read wikipedias entry for truth tables. Right away, you're probably seeing the #1 problem with this encryption scheme. Too small a keyspace, or in other words, there are so few possible keys that this can be easily brute forced.
Lets examine: there are approximately 3.4 billion possible keys (0-3435973836). Compare this to a simple 8 character password using only characters from the set [a-z]. The keyspace here is 26^8 or 208827064576 which is over 208 billion possible keys. How long would it take your password cracker to incrementally crack a password that was known to be 8 characters in the set [a-z]? Not very long, and that password is over 65 times stronger than any key for this program.
Now here's the difference between hacking and ...cracking or whatever other awkward label you use. I could stop here, write a little program to implement the brute forcing and be done with it, or I could keep hacking at it to see if there's an even more efficient way. You know me, of course I'll keep going... And heres where all the trouble started ;)
Lets take a look at how shush uses the key to encrypt the file (the shush.c source is available below this description, use it as a reference). When you give shush your integer, shush passes it to a function called srand(). This function uses the integer as an initial value for generating "random" numbers with the rand() function. This concept is called seeding. To be as basic as I possibly can... The SEED is a number that the random number generator does weird math stuff with. Once its done its weird math stuff, the result is the random number thats been generated, that result ALSO becomes the new seed. Here's some psuedo code to represent this:
seed = 31337
Generate random number:
random_number = seed + 1234 * 4321 / 7
seed = random_number
Now this is VERY arbitrary. The "weird math stuff" is actually quite technical, but far from within the scope of this post. For more information on this stuff research Linear congruential generators.
The point to note here is that this "weird math stuff" is an algorithm, and if you think about it... there is nothing truly "random" about mathematical algorithms. Thats why we call this algorithmic randomness "psuedorandom". And we call this generator a "psuedorandom number generator" (hereafter PRNG).
It might seem like i'm on a tangent, but trust me its relevant.
So, basically You give shush an integer, this integer becomes a SEED. Shush then gets into a loop. This loop reads in one byte, and performs an XOR operation on that byte against the result of a call to the PRNG. This PRNG is actually the function rand(). Keep that psuedo code in mind, everytime rand() is called, the seed changes, and so, the next time its called the result is different. The result of this XOR operation becomes the value for the encrypted byte, and so is written out to the encrypted file.
Here is shush.c
#include <stdio.h>
#include <stdlib.h>
void XOR(char filename[], unsigned key)
{
FILE * in, * out;
srand(key);
unsigned ascii;
char tempfilename[9999];
sprintf(tempfilename,"%s%s",filename,".temp");
if ((in = fopen(filename, "rb")) == NULL) printf("Error: Could not open: %s\n",filename);
else if ((out = fopen(tempfilename, "wb")) == NULL) printf("Error: Could not open: %s\n",tempfilename);
else
{
while((ascii = fgetc(in)) != EOF) fputc(ascii^rand(),out);
fclose(in);
fclose(out);
remove(filename);
rename(tempfilename,filename);
}
}
void main(unsigned argc, char * argv[])
{
printf("XOR File Encryption v1.0\nProgrammed by xxx\nEmail: xxx\n\n");
if (argc==1) printf("Error: No file(s) supplied.\n");
else
{
unsigned key, counter=1;
printf("List:\n");
while (counter<argc)
{
printf("[%u] %s\n",counter,argv[counter]);
counter++;
}
counter=1;
printf("\nKey [0:3435973836]: ");
scanf("%u", &key);
printf("\nOne moment please. Processing...\nTo cancel, press ctrl + c\n\nStatus:\n");
while (counter<argc)
{
printf("[%u] %s...",counter,argv[counter]);
XOR(argv[counter],key);
counter++;
printf("done\n");
}
}
system("pause");
}
If you're following me, this will make sense. Based on the fact that rand() uses a static algorithm, the sequence of numbers it returns will always be the same sequence for a particular seed. With a symmetrical stream cipher like this XOR scheme, this is useful. I'll demonstrate.
Lets look at this sequence of numbers: 1, 2, 3, 4. We'll use them to "XOR encrypt" these 4 values: 5, 5, 5, 5. In a realworld example, these numbers would be numerical representations of the byte's from the file.
as XOR is a bitwise operator, Lets see these in binary form:
00000101 00000101 00000101 00000101 (5, 5, 5, 5: unencrypted)
00000001 00000010 00000011 00000100 (1, 2, 3, 4: KEY)
-------------------------------------------------------------
00000100 00000111 00000110 00000001 (4, 7, 6, 1: encrypted)
This is what happens when you run shush on a file... Now, you send that file to someone and they run shush with the same key, and this happens:
00000100 00000111 00000110 00000001 (4, 7, 6, 1: encrypted)
00000001 00000010 00000011 00000100 (1, 2, 3, 4: KEY)
-----------------------------------------------------------
00000101 00000101 00000101 00000101 (5, 5, 5, 5: decrypted!)
This is the concept of a symetrical encryption scheme. Now lets review what we know. The user supplies an integer. This integer seeds rand(). Rand generates a sequence of numbers against which each byte in the file is XOR'd, the results make up the encrypted file.
Now that we understand shush more thoroughly, we can design an attack. My theory was this:
The user supplies a key that seeds rand(), rand() then returns a predefined algorithmic series of numbers. Since this is algorithmic, given any number in the series, I will be able to predict the next number, or even the previous number in the series. Therefore if ANY of those numbers are known to me, I can reverse the algorithm to get the key. With that key, I can decrypt the file. This is pretty standard, the question is how can I find any of these numbers? Well, really I shouldn't be able to... but a weakness in the implementation gives me a leg up. When a file is encrypted with shush, it keeps its filename. This means that, for a lot of file formats, SOME of the plaintext characters will be known. For instance, every valid JPG will have the same first 4 bytes (have a look if you want to verify). These are file headers. The nature of XOR allows us to use these known values to extract part of the key!
(OKAY WAIT. Here is where we're going to get mixed up with our terminology... when I say "key" I'm talking about the integer the user gave to shush. When I say "part of the key" i'm not talking about part of that number, I'm talking about one value returned by rand()... This might be confusing, but assume the integer supplied by the user to be 'the same thing' as the series of numbers returned by rand(). )
Lets look at how this works. Lets say we're looking at the first four bytes of the encrypted file (same values as the last examples) and in this case we KNOW (based on file format specifications) that these bytes were originally 5, 5, 5, 5 before being encrypted.
00000100 00000111 00000110 00000001 (4, 7, 6, 1: encrypted)
00000101 00000101 00000101 00000101 (5, 5, 5, 5: unencrypted)
-------------------------------------------------------------
00000001 00000010 00000011 00000100 (1, 2, 3, 4: KEY!)
Now that we've extracted some of the numbers returned by rand(), all we need to do is reverse the algorithm in rand() to determine what key was given to srand(), and the encryption is defeated. This is A LOT faster than brute forcing... Everything looks good Right? hmm....
If anyone see's a problem here you get props. I didn't see a problem until I started experimenting. My theory seems pretty solid, but (my c++ prof loves to call me on this) I'm making an assumption. XOR is bitwise. Shush takes 1 byte from the file, and XOR's it against 1 integer returned by rand(). Until now, we've been assuming that both of these peices of data were of the same size. Thats assuming that rand() can only generate 8bit integers, making the maximum value 255 (unsigned). This isn't the case, after experimenting with rand() for a bit, its clear that rand() returns values outside that range. So lets see what happens when we XOR two values with different bit lengths, we'll use the same values as before, but we'll change one number from the key:
00000101 00000101 00000101 000000101 (5, 5, 5, 5 : unencrypted)
00000001 00000010 00000011 110010000 (1, 2, 3, 400: KEY)
-------------------------------------------------------------
00000100 00000111 00000110 110010101 (4, 7, 6, 405: encrypted)
Notice that the fourth value returned by rand() this time is to 400, this makes the bit length 9 instead of 8. Since the key changed in bit length, a 0 was padded to the beginning of the value it is being XOR'd against, and the encrypted value ends up being 9 bits as well. Since we're writing byte values out to a file, only 8 of those bits will actually be used, 1 will be discarded. Lost Forever. This complicates our methodology, watch (remember the encrypted value was 110010101, or 405, but when the most significant bit is discarded, it becomes 10010101, or 149):
10010101 (149: encrypted)
00000101 (5 : Known unencrypted value)
--------------------------------------
10010000 (144: key? ...)
Flawed logic gave us a false positive. the key is 400, not 144... So if rand() returns a value greater than 255, our attack fails. Right? well... To an extent. Think of it on a bit level... The value of the actual key, versus the value or the key we got are actually pretty close when we look at it this way:
110010000
10010000
Basically, we still know the last 8 bits of the key no matter what. So we could build a set of potentials based how many values rand() can return that end in our 8 bits. In order to do this we need to know the largest possible value rand() can give us. This value changes from compiler to compiler (remember this, I'll come back to it.) and its set in cstdlib/stdlib.h as RAND_MAX. In the compiler I use (mingw), it's set to 0x7fff, or 32767 which is 15 bits. So how many potential values exist when the last 8 bits are known? 2^7 == 128 possible values. Thats a pretty small keyspace, compared to the 3.4 billion we were dealing with before...
Incase anyones lost, quick review:
We xor a byte from the encrypted file against what we KNOW was the original byte before it was encrypted. The result becomes the final 8 bits of what that byte was originaly xor'd with by shush. This gives us a set of 128 potential values. Now we can reverse the algorithm in rand(), and determine 128 potential keys one of which was originally supplied to shush by the user.
If anyone see's a problem HERE, again... props. There's something I didn't take into account. We've been assuming that in rand() is a symmetrical algorithm that can be reversed. I think the reason I thought this was because in most descriptions of rand(), they talk about algorithmic randomness, and in pure mathematics algorithms are symmetrical but in programming, not necesarilly. Here is what rand() does (this is the implementation used by mingw, it also changes between compilers, I've also changed how it looks a bit for simplicity, it still functions the same.)
return((seed = seed * 214013L + 2531011L) >> 16);
As you can see, it takes the seed (your key) and multiplies it by 214013, the product of that is added to 2531011. If this was all, it could be trivially reversed. We'd take the result, subtract 2531011 and divide the difference by 214013. But there's more. >> 16 indicates that 16 bits are dropped off the end of the value... And again, lost forever. So this introduces a whole new set of potentials... How many? well... remember the maximum allowed seed (as indicated by shush) is: 3435973836, which is a 32bit value. 16 of those bits are discarded from the seed. This means that for every number from our list of 128 potentials there is 2^16 or 65536 additional potentials. This gives us 8388608 potentials in all. Still beats brute-forcing.
Their's a question to ask yourself at this point though. A modern computer can crunch 3.4 billion numbers in seconds. So does the difference in efficiency and execution time justify the complexity of the code required to accomplish it? Probably not to the average user. If this was a professional developer project, your boss would kick you in the ass for wasting so much time. But it was a lot of fun anyways.
One side note is that shush is depending on rand(). Through my research, I learned that rand() has no standard. Its implemented differently on many different platforms, and in different compilers, and even changes from version to version. This program would be mostly useless if it was released opensource, as if two users compiled it with different compilers, chances are it would fail.
Anyways, hope SOMEONE had fun reading this lol
Monday, August 07, 2006
Authentication bypass.
This is an example of a far too common problem. Developers have a tendency to assume that client applications will always act how they were designed to act. This is fine if you're depending on them for functionality, but NOT if you're depending on them for security.
Recently I was asked to take a peek at a content management system currently in developement. A lot of it seemed relatively stable, except for this one short snippet of code. Whenever a protected page is loaded, one that you have to be logged in to view, a function containing this code is called:
It grabs a variable called 'privLvl' registered to the users session. If the user is not logged in, this variable is unset and the browser is redirected to the login page. So then, what is the problem? The problem exists, because our developer is putting his trust in a function that depends on the browsers response. header("Location: login.php"); will force a browser to redirect to login.php, but only because that is how a browser is programmed to react. watch what happens when I load this page in ie, then in netcat:
first, here is the code for admin.php:
Here is an image of what loads in IE:
that form is what is stored in login.php, we've been happily redirected, as intended. And now, in netcat:

Whoops. Netcat has no idea what to do with the Location: header, its not a browser. A secure way to implement this would be as follows:
Here we force exit of the script after redirect, incase the client doesn't listen.
There are plenty of other vulnerabilities based on this same flawed thinking. Using javascript to sanatize input is a common one. As a developer you should always be concious of what your functions depend on, and whether or not those dependencies are under your control.
Recently I was asked to take a peek at a content management system currently in developement. A lot of it seemed relatively stable, except for this one short snippet of code. Whenever a protected page is loaded, one that you have to be logged in to view, a function containing this code is called:
if(!isset($_SESSION['session']["privLvl"])) {
header("Location: login.php");
}
It grabs a variable called 'privLvl' registered to the users session. If the user is not logged in, this variable is unset and the browser is redirected to the login page. So then, what is the problem? The problem exists, because our developer is putting his trust in a function that depends on the browsers response. header("Location: login.php"); will force a browser to redirect to login.php, but only because that is how a browser is programmed to react. watch what happens when I load this page in ie, then in netcat:
first, here is the code for admin.php:
<?
if(!isset($_SESSION['session']["privLvl"])) {
header("Location: login.php");
}
echo "BIG SECRET!";
?>
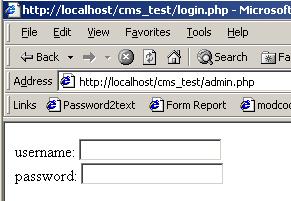
Here is an image of what loads in IE:
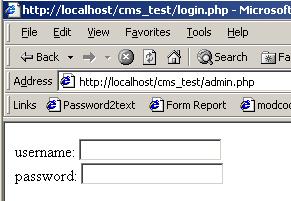
that form is what is stored in login.php, we've been happily redirected, as intended. And now, in netcat:
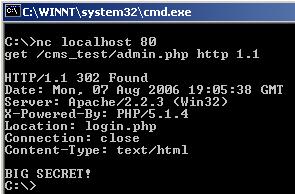
Whoops. Netcat has no idea what to do with the Location: header, its not a browser. A secure way to implement this would be as follows:
<?
if(!isset($_SESSION['session']["privLvl"])) {
header("Location: login.php");
exit();
}
echo "BIG SECRET!";
?>
Here we force exit of the script after redirect, incase the client doesn't listen.
There are plenty of other vulnerabilities based on this same flawed thinking. Using javascript to sanatize input is a common one. As a developer you should always be concious of what your functions depend on, and whether or not those dependencies are under your control.
Thursday, August 03, 2006
New Bookmarklets
I developed a few new web app pentesting bookmarklets this afternoon. If anyone has any requests, or bookmarklets of their own to share, please leave me a comment.
Here are the new ones:
Password2text: for quickly viewing whats in a password input.
Form Report: Detailed report of all forms on the current page.
Here is a running list of all my security marklets so far:
modcookie: For on-the-fly cookie modification.
methodToggle: for toggling the method of a form, to test method strictness
noMax: removes the maxlength property of text inputs.
hidden2text: displays hidden inputs.
I'll be looking forward to requests, and other security marklets from all of you ;)
Here are the new ones:
Password2text: for quickly viewing whats in a password input.
Form Report: Detailed report of all forms on the current page.
Here is a running list of all my security marklets so far:
modcookie: For on-the-fly cookie modification.
methodToggle: for toggling the method of a form, to test method strictness
noMax: removes the maxlength property of text inputs.
hidden2text: displays hidden inputs.
I'll be looking forward to requests, and other security marklets from all of you ;)
Subscribe to:
Posts (Atom)


